A Deeper Look into the Supernova Remnant Vela Junior
June 2017
Most of the cosmic rays that constantly bombard Earth's Atmosphere have their origin in cosmic particle accelerators within our Galaxy, the Milky Way. H.E.S.S. found various types of such accelerators in the past decade, but shell-type supernova remnants (SNRs) remain the likely dominant contributor to this sea of diffuse, sub-atomic particles. Shock waves of SNRs expand over hundreds of light years into interstellar space, and are thought to accelerate electrons, protons and heavier nuclei. One very prominent supernova shell, first detected in the X-ray band [1], is Vela Junior, or RX J0852.0-4622. It receives its common name from the fact that it is superimposed to the much larger Vela SNR (see Fig. 1). It is likely farther away than the Vela SNR, but still one of the closest TeV sources, at 2400 light years from Earth.
Remarkably, Vela Junior is one of only a few SNRs whose shell morphology has been resolved in gamma rays. The other objects of this group are SNR RX J1713.7-3946, SN 1006, HESS J1731-347, RCW 86, and HESS J1534-571. Moreover, the properties of Vela Junior and RX J1713.7-3946 are quite similar: both are young (around a thousand years), nearby (distance < 1.5 kpc), and therefore appearing very extended (diameter > 0.5°); they are comparably bright, and the emission in X-ray and radio has a continuous spectrum that suggests the presence of accelerated, highly energetic particles. Detailed studies of Vela Junior's properties are crucial for the understanding of the processes that occur in SNRs, in particular the mechanisms through which SNRs accelerate particles up to the highest energies, and their role in the 100-years long-standing enigma of the origin of Galactic cosmic rays.
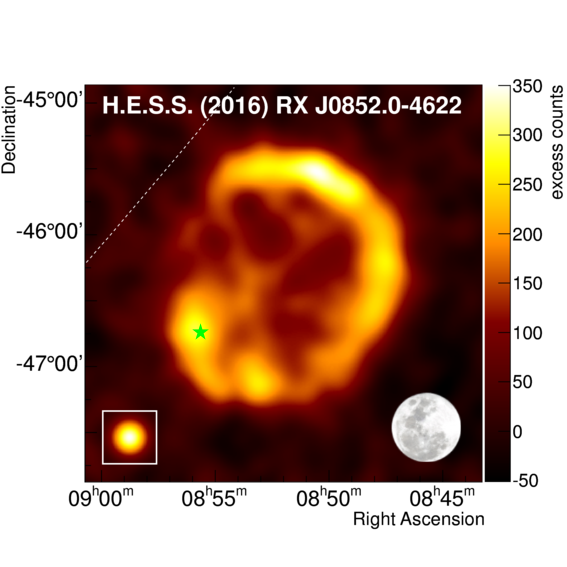
Since the last H.E.S.S. publication [2], the amount of data available for Vela Junior has roughly doubled, allowing a much deeper study of this object. The morphology of the gamma-ray emission seen by H.E.S.S. is that of an arc (shell) from North, through West, to South (see Fig. 2). Significant emission is also detected from the centre and a local enhancement towards the South-East, matching the position of the energetic pulsar PSR J0855-4644. The enhancement detected towards the pulsar suggests that some of the emission might come from a possible pulsar wind nebula associated to the pulsar. Its contribution is estimated to be less than 8% of the flux of the whole region, i.e. relatively small compared to the emission from the SNR.
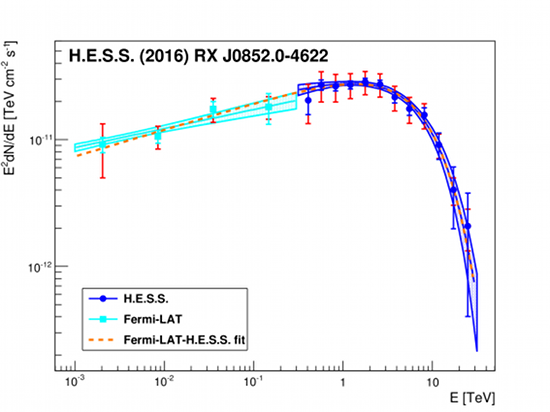
To investigate the properties of the relativistic particles that are present in the shell, causing the gamma-ray emission that is observed, we examined the energy spectrum of the emission. Firstly, our updated flux measurement makes Vela Junior the brightest steady source in the sky above 1 TeV, with a flux 13% larger than the flux of the Crab nebula in the same energy range. Secondly, the spectrum is clearly curved: it can be described by a power-law with an exponential cut-off at energy Ecut = 6.7 ± 1.2stat ± 1.2syst TeV (see Fig. 3). The H.E.S.S. spectrum connects well to the Fermi-LAT measurement at GeV energies, without need for a spectral break as in previous publications [3]. This smooth connection of the GeV and TeV data, together with the well-defined cut-off, allows a direct determination of the characteristics of the parent particle population using gamma-ray data only.
Spatially-resolved spectroscopy reveals no clear spectral variation across the source, suggesting that the parent particle population can be assumed to be the same throughout the remnant, which in turn indicates that the conditions for particle acceleration, i.e. properties of the SNR shock and ambient medium, are similar everywhere.
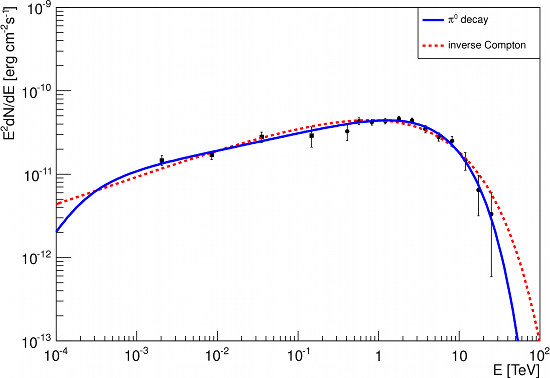
The origin of the gamma-ray emission in SNRs, either leptonic (relativistic electrons scattering off ambient photons) or hadronic (highly energetic protons colliding with ambient matter), keeps being a matter of intense debate. Fig. 4 shows fits of such models to the Fermi-LAT and H.E.S.S. data. Unfortunately, even with our new results we cannot distinguish which of these two scenarios is currently at work in Vela Junior. For that, deeper observations at both lower energies (in particular in the MeV band) and higher energies (above 10 TeV) would be needed.
However, for each of these scenarios, our data can be used to determine important source properties: in the leptonic case, the magnetic field strength within the Vela Junior region can be estimated at a relatively low value of about 7 μG. In a hadronic scenario, the total amount of energy in accelerated protons would be less than about 10% of the SNR explosion energy, imposing at the same time a limit on the ambient medium density of about 1 cm-3 (for the assumed distance to the source of 750 pc).
Even if it is still not possible at this point in time to identify the driver of the gamma-ray emission in Vela Junior (either electrons or protons, or a combination of both), H.E.S.S. observations have provided the most accurate characterisation of source properties ever obtained in gamma rays for this unique SNR. Deeper insights at this energy range may only be possible with future instrumentation like CTA, offering an order-of-magnitude sensitivity improvement and a better angular resolution at TeV energies.
References:
H.E.S.S. Collaboration, H. Abdalla et al.,
"Deeper H.E.S.S. Observations of Vela Junior (RX J0852.0-4622):
Morphology Studies and Resolved Spectroscopy",
arXiv 1611.01863,
accepted for publication in Astronomy & Astrophysics
[1] B. Aschenbach,
"Discovery of a young nearby supernova remnant",
Nature 396 (1998) 141
[2] H.E.S.S. Collaboration, F. Aharonian et al.,
"H.E.S.S. Observations of the Supernova Remnant RX J0852.0-4622:
Shell-Type Morphology and Spectrum of a Widely Extended Very High
Energy Gamma-Ray Source",
The Astrophysical Journal 661
(2007) 236
[3] T. Tanaka et al.,
"Gamma-Ray Observations of the Supernova Remnant RX J0852.0-4622 with
the Fermi Large Area Telescope",
The Astrophysical Journal Letters 740 (2011) L51